A Java Time Series Columnar Store
In my previous post, “A case for in-memory columnar data structures”, I used a JMH benchmark to show that if what we need to do is calculate statistical indicators over an object field ( metric ), destructuring data and store successive values of that metric in a continuous array is (much) more efficient than storing the same information in structured POJOs.
Storing the metric variable in a continuous array works well with the kind of computation we’re performing: we race through a continuous chunk of memory and we access successive locations in predictable, in uniform strides. When we access the first element of the array, the CPU will bring an entire cache line from main memory into level 1 cache. This means the next N items we need will be brought into cache in the same transaction and will be immediately available at a very low cost. This way, we’ll get the highest cache hit rate possible which implies the lowest memory access cost possible.
This is what we call space and time locality: data items that are used together and at about the same time, are stored close to each other in memory.
And because we access memory in constant, predictable strides, the CPU will be able to reliably guess which memory chunk well need next and pre-fetch it, minimizing the time required to make that new memory chunk available in cache.
The above considerations are universally applicable to any programming language, from languages running on top of the JVM, .Net or other managed run-times to system languages such C or C++. For higher level, garbage collected languages such as Java, the technique yields another very important advantage: less back-pressure on the garbage collector.
Indeed, if you look at a large data set, say one billion items, and you do it the naive way by allocating one object per data item, that’s one billion objects the garbage collector needs to keep track off. Not only does this mean the JVM will spend a lot of CPU cycles managing object references, it will also use a significant amount of memory for that. With the columnar approach, that will be one billion objects the GC does not have to keep track of. Those CPU cycles used to manage memory will become available for useful computations instead.
Each object allocation does not only allocate memory for the fields but also for some metadata. When you allocate a billion objects, the amount of memory reserved for object metadata becomes significant. If you go the columnar way and avoid allocating one billion objects, the amount of memory that would otherwise be filled with object metadata will be available to store some extra domain data.
We’ve seen that columnar data stores offer both time and space performance improvements, but from a programming point of view, is it practical and easy enough to be adopted by a majority of developers?
It seems like in order to use columnar stores we have to give up object oriented programming. If our data item is a weather observation item that records time, air temperature, humidity and wind speed a typical OOP developer will create a WeatherObservation class with four fields. When recording a new observation, they would instantiate a new WeatherObservation and add it to a collection.
With a columnar store approach, it looks like we need to allocate N different arrays and when recording a new observation, we need to increment an array index and set the appropriate value in each of the arrays. This looks like an overly manual and error prone process. It would be great if we could have a columnar store wrapped in a nice collections like API, or at least something that allows us to access data in the columnar store in an object oriented manner.
When we design our easy to use columnar store, we can’t have a EnvObservation POJO because that’s not how we want to store our data, but if we think about it, from an OOP perspective, the important parts of the POJO are not the fields, but it’s getters and setters because as per Java Beans conventions, that’s how we access the fields. Instead of having a EnvObservation POJO, we can could have an EnvObservation interface:
Now we need to think about a collection like data structure that satisfies the following requirements:
- it must be a columnar store
- it must allow access to individual items through the domain object interface — in our case, EnvObservation — in arbitrary order.
- it must minimize object allocation
- It must provide iterators and streams of EnvObservation, as well as streams of primitive values for each metric variable
- it must allow for efficient calculation of statistical indicators of each domain object field, to take advantage of the columnar nature of the data structure
The EnvObsTimeSeries class bellow satisfies all these requirements:
Does EnvObsTimeSeries satisfy our requirements? It stores item fields in continuous arrays so it is a columnar store. Requirement 1) is satisfied.
We can access any observation item through the getEnvironmentObservation method. This returns an implementation of the EnvObservationItem interface. Requirement 2) is satisfied.
Does it minimize object allocation? Yes it does, and this is how:
- to store 1 billion items, instead of allocating 1 billion EnvObservationItem instances we only allocate 5 arrays, one per field. We cannot do much better than this.
- we do not need to allocate an EnvObservationItem to add it to the store. We are using the emplace methods that store metric variables primitive values in each respective arrays at the right location. Emplacement is a technique used by C++ STL vectors to add an item (meaning, the object itself, not a pointer to it) to a vector by constructing it in place. Of course, in C++ this also has other advantages: you only construct the object once and you avoid unnecessarily using the copy constructor.
- One may argue that when you call getEnvironmentObservation or when you traverse the store using the iterator or stream accessors, a new instance of EnvObservationItem is allocated each time you access an item. If you take a closer look at the source code, you’ll notice ArbitraryAccessCursor has an “at” method. This method allows you to point the cursor ( which implements EnvObservation, by the way ) to any item in the store without having to allocate new objects. Same principles applies to iterators — and implicitly, streams — you obtain from the store: moving to a new element does not allocate a new object.
Requirement 3) is satisfied.
It does provide methods to obtains iterators and streams of EnvObservation, so requirement 4) is satisfied.
And it does provide methods to obtain streams of primitive values for each individual EnvObservation field that can be traversed in the most cache efficient manner, so requirement 5) is satisfied as well.
Additionally, EnvObsTimeSeries holds time series data so a few methods are also provided to facilitate processing of items in a specific time frame.
So here we are, we now have a data structure that satisfies all our requirements, mainly:
- allow for most cache efficient access to variable sequences, as a consequence allowing for most efficient calculation of statistical indicators. Because cache efficiency is at its maximum, all the CPU cycles you would otherwise waste by waiting for data to be transferred from main memory to cache are now available for useful computations.
- stay as low as possible on allocations — we reduced the number of allocated objects from O(n) to just a few arrays. On one hand, this reduces stop-the-world GC pauses because the GC has less objects to manage and on the other, all CPU cycles previously used to monitor allocated objects and perform all the GC housekeeping are now available for useful computations.
- Last but not least, this data structure allows us to access and work with your data in an object oriented manner, while preserving all goodies induced by the columnar store.
The only other issue we may object to is that this is a lot of boilerplate to write each time we need to process time series data. But this obstacle can be removed as well and we will talk about it in the next article.
Proof. This sounds great but we’re (computer) scientists and we are not supposed to just take anyone’s claims for granted. So in order to sustain the performance improvement claims, bellow are the results of JMH tests ran against this implementation.
The tests measure the performance of calculating the average temperature of one of the metrics in our EnvObservationItem, namely the temperature. There are two families of benchmarks, one against a classic approach where data is stored in regular java beans stored in an array list and one where data is stored in the columnar data structure.
There are two classic benchmarks:
- ClassicBenchmark — the test immediately allocates all objects and adds them to the array list. If the JVM has a free memory area on the heap that is big enough to contain all these objects and nothing else is happening in the JVM — and for our test, this is in fact the case — chances are they will be allocated on continuously. The average is calculated by obtaining a stream over the array list.
- ClassicBenchmarkShuffled — like ClassicBenchmark, except that after adding the objects to the array we shuffle them to simulate a truly random allocation pattern.
There are 4 columnar benchmarks
- CursorBenchmark — manually calculates the average by traversing the temperature column using the data structure’s cursor
- IteratorBenchmark — like CursorBenchmark but uses an iterator to traverse the temperature column
- ObjectStreamBenchmark — obtains a stream of EnvObservationItem from the columnar structure and user the stream API to calculate the average
- StreamBenchmark — obtains DoubleStream over the temparature column and uses that API to calculate the average
By examining performance harness results we notice that the columnar approach improves performance by a factor of 10 to 30 over the traditional approach, depending on how chaotic your object allocation patterns get.
Throughput benchmark results:
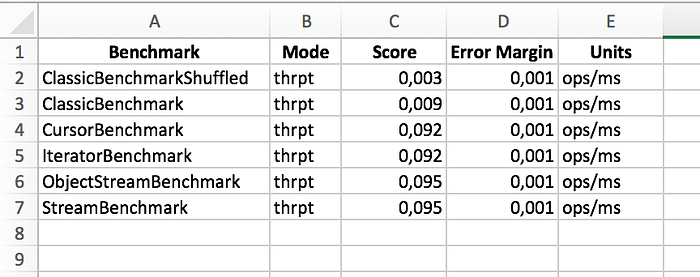

Performance benchmark results
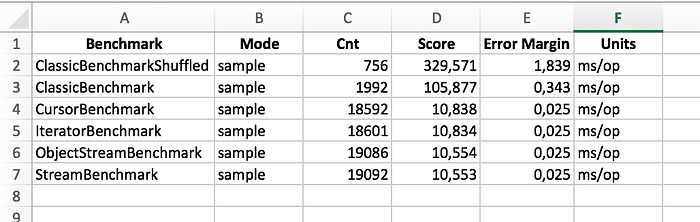
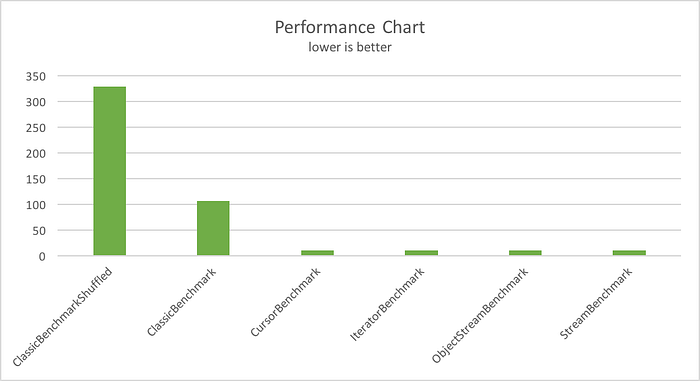
The JMH test is bellow:
Get all the code from GitHub: https://github.com/entzik/acropolis-concept
